卷积神经网络(Convolutional neural network,即CNN)是受人类视觉皮层生物过程的启发而建立的多层神经元模型,非常适合目标识别和面部检测等任务,然而在精度达到一定程度后,想进一步提高就需要非常繁琐的微调。为此,Google人工智能研究部门的科学家们研究了一种新模型,这种模型能够以“更结构化”的方式“扩展”CNN的规模。
最近他们在Arxiv.org上发表的一篇名为“EfficientNet:重新思考卷积神经网络的模型扩展”的论文(https://arxiv.org/abs/1905.11946),还有一篇博客文章(https://ai.googleblog.com/2019/05/efficientnet-improving-accuracy-and.html)对此进行了描述。
该论文的作者称,这一系列被称为EfficientNets的人工智能系统,能够超越目前最先进的AI模型的准确率,同时效率最多能提高10倍。
“传统的扩展模型的做法是任意增加CNN的深度或广度,或者使用更高分辨率的输入图形进行训练和评估,”Google软件工程师Mingxing Tan与Google AI首席科学家Quoc V. Le写道:“与任意扩展网络维度的传统方法(比如深度、广度或分辨率)不同,我们的方法通过一组固定的扩展系数来均匀地扩展各个维度。”
那么,具体如何实现呢?首先,通过网格搜索,确定在固定资源约束下(例如,将浮点数计算次数或每秒浮点运算次数增加两倍)基准网络的各个扩展维度之间的关系。这一步能够确定每个维度的适当扩展系数,接下来我们可以利用这些系数将基准网络扩展到期望的模型或预定的计算量。
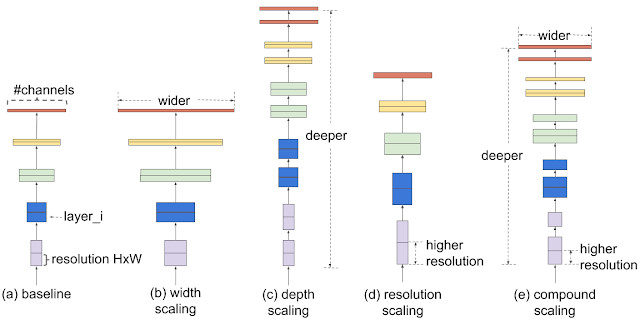
不同的扩展方法的比较,图片来源:Google
为了进一步提高性能,研究人员提倡使用一种新的基准网络——移动翻转瓶颈卷积网络(mobile inverted bottleneck convolution,MBConv),这种神经网络是EfficientNets模型系列的核心。
在测试中,与现有的CNN相比,EfficientNets体现出更高的准确率和效率,它将参数大小和每秒浮点运算次数(FLOPS)降低了一个数量级。其中的一个模型EfficientNet-B7,比高性能的CNN Gpipe小8.4倍,速度快6.1倍,在ImageNet上达到了Top1准确率84.4%和Top5准确率97.1%。与流行的ResNet-50相比,另一个模型EfficientNet-B4可以在相同FLOPS条件下,同将Top1准确率从76.3%提高到82.6%。
此外,EfficientNets在其他数据集上的表现也很好,在8个数据集中有5个达到了最先进的准确率,包括CIFAR-100(91.7%的准确率)和Flowers(98.8%的准确率),同时参数减少了21个。
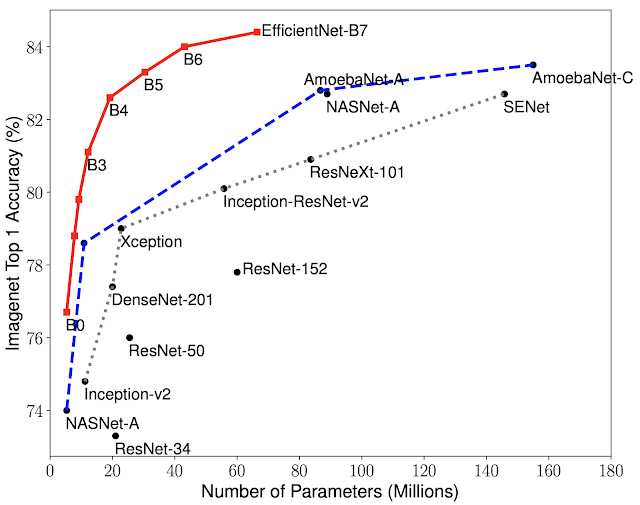
模型规模与准确率的比较,图片来源:Google
Google在GitHub上公开了云托管张量处理单元(TPU)的源代码和训练脚本(https://github.com/tensorflow/tpu/tree/master/models/official/efficientnet)。Tan和Le写道:“通过显著提高模型的效率,我们预计EfficientNets有望成为未来计算机视觉技术的新基础。”
原文:https://venturebeat.com/2019/05/29/googles-efficientnets-is-faster-at-analyzing-images-than-other-ai-models/
本文转自CSDN